Featured projects
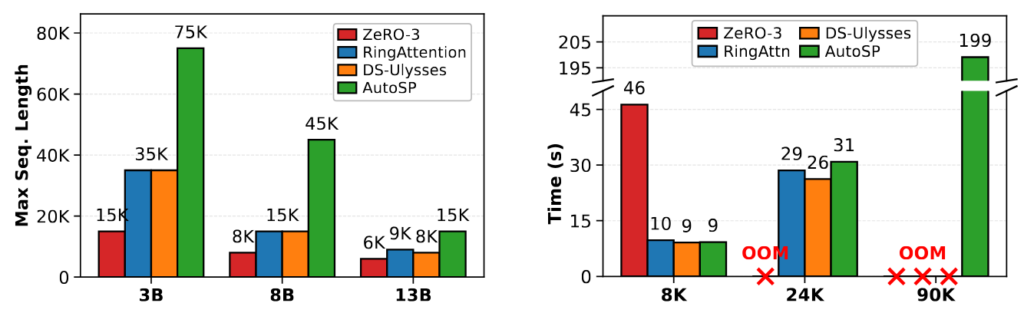
Increasingly, Large-Language-Models (LLMs) are being trained for extremely long-context tasks, where token counts can exceed 100k+. At these token counts, out-of-memory (OOM) issues start to surface, even when scaling device counts using conventional training techniques such as ZeRO/FSDP. To circumvent these issues, sequence parallelism (SP): partitioning the input tokens across ...