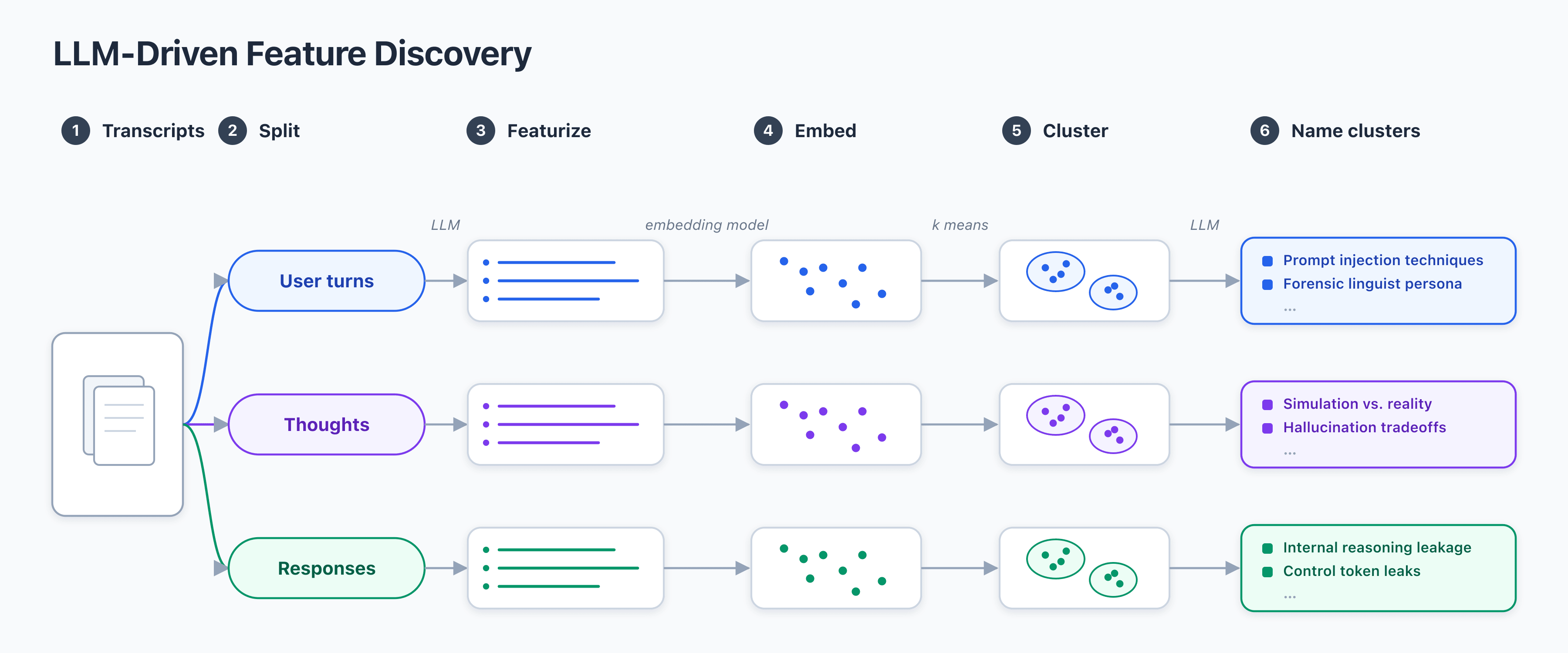
I did some related work with mentees last year that extends EDW by using an unsupervised optimisation target: the average CE loss of an LLM on items in the dataset when given the featurisation of the item in the prompt (https://arxiv.org/abs/2502.17541 That kind of approach can help you prioritise the features which explains the dataset you're investigating the most (kind of a natural language P...