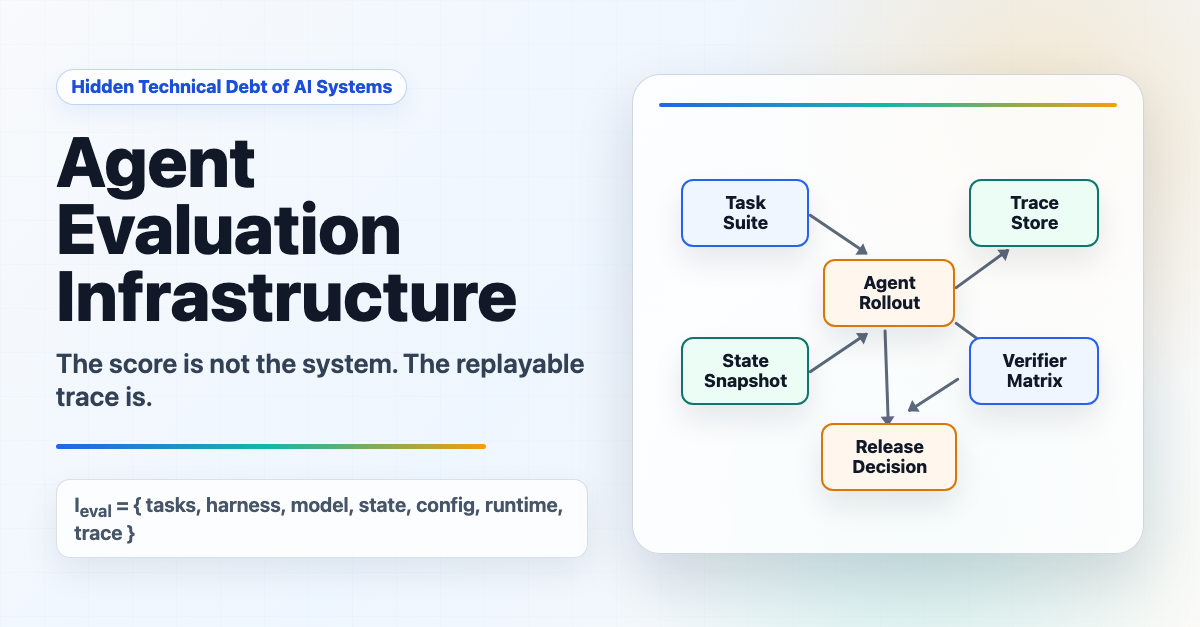
Hidden Technical Debt of AI Systems: Agent Evaluation Infrastructure
Most conversations about evals collapse into which SaaS tool to buy, which metrics to track, which LLM-as-a-judge prompt to slap on, or which single headline benchmark score to worship. SWE-bench percentage. Humanity’s Last Exam. ARC-AGI. Pokémon Red. Or most often, a directive from the top saying LGTM. These scores are useful, b...